
Data Cleaning
Sebuah model Machine Learning tidak mampu untuk langsung / seketika mengolah data yang kita temukan dari berbagai sumber. Ada istilah Garbage In - Garbage Out yang berarti hasil dari machine learning akan buruk jika input yang Anda masukkan juga buruk.
Tidak seluruh data yang kita dapat dari berbagai sumber siap untuk langsung diberikan ke sebuah model machine learning. Perolehan data memiliki banyak kekurangan, sehingga perlu Anda olah terlebih dahulu.
Berikut adalah beberapa hal yang umum yang harus diperhatikan dalam proses data cleaning:
- Konsistensi Format
Sebuah variabel mungkin tidak memiliki format yang konsisten seperti penulisan tanggal 10-Okt-2020 versus 10/10/20. Format jam yang berbeda seperti 17.10 versus 5.10 pm. Penulisan uang seperti 17000 versus Rp 17.000. Data dengan format berbeda tidak akan bisa diolah oleh model machine learning. Solusinya, format data harus konsisten. - Skala Data
Jika sebuah variabel memiliki jangka dari 1 sampai 100, pastikan tidak ada data yang lebih dari 100. Untuk data numerik, jika sebuah variabel merupakan bilangan positif, maka pastikan tidak ada bilangan negatif. - Duplikasi dataData yang memiliki duplikat akan mempengaruhi model machine learning, apalagi data yang duplikat memiliki jumlah yang besar. Untuk itu kita harus memastikan tidak ada data yang terduplikasi.
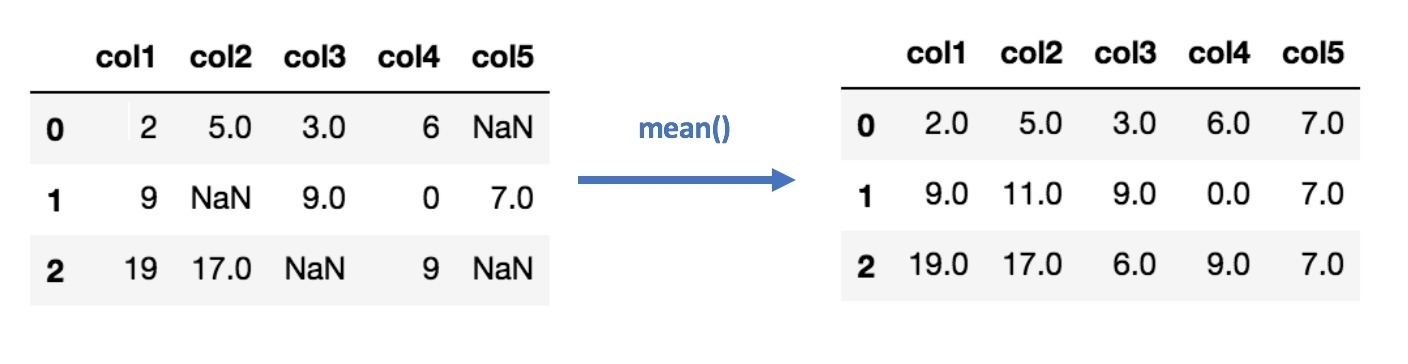
- Missing ValueMissing value terjadi ketika data dari sebuah record tidak lengkap. Missing value sangat mempengaruhi performa model machine learning. Ada dua opsi untuk mengatasi missing value, yaitu menghilangkan data missing value atau mengganti nilai yang hilang dengan nilai lain, seperti rata-rata dari kolom tersebut atau nilai yang paling sering muncul.
- Skewness
Skewness adalah kondisi di mana dataset cenderung memiliki distribusi data yang tidak seimbang. Skewness akan mempengaruhi data dengan menciptakan bias terhadap model. Apa itu bias? Sebuah model cenderung memprediksi sesuatu karena ia lebih sering mempelajari hal tersebut. Misalkan ada sebuah model untuk pengenalan buah di mana jumlah jeruk 92 buah dan apel 8 buah. Distribusi yang tidak imbang ini akan mengakibatkan model lebih cenderung memprediksi jeruk daripada apel.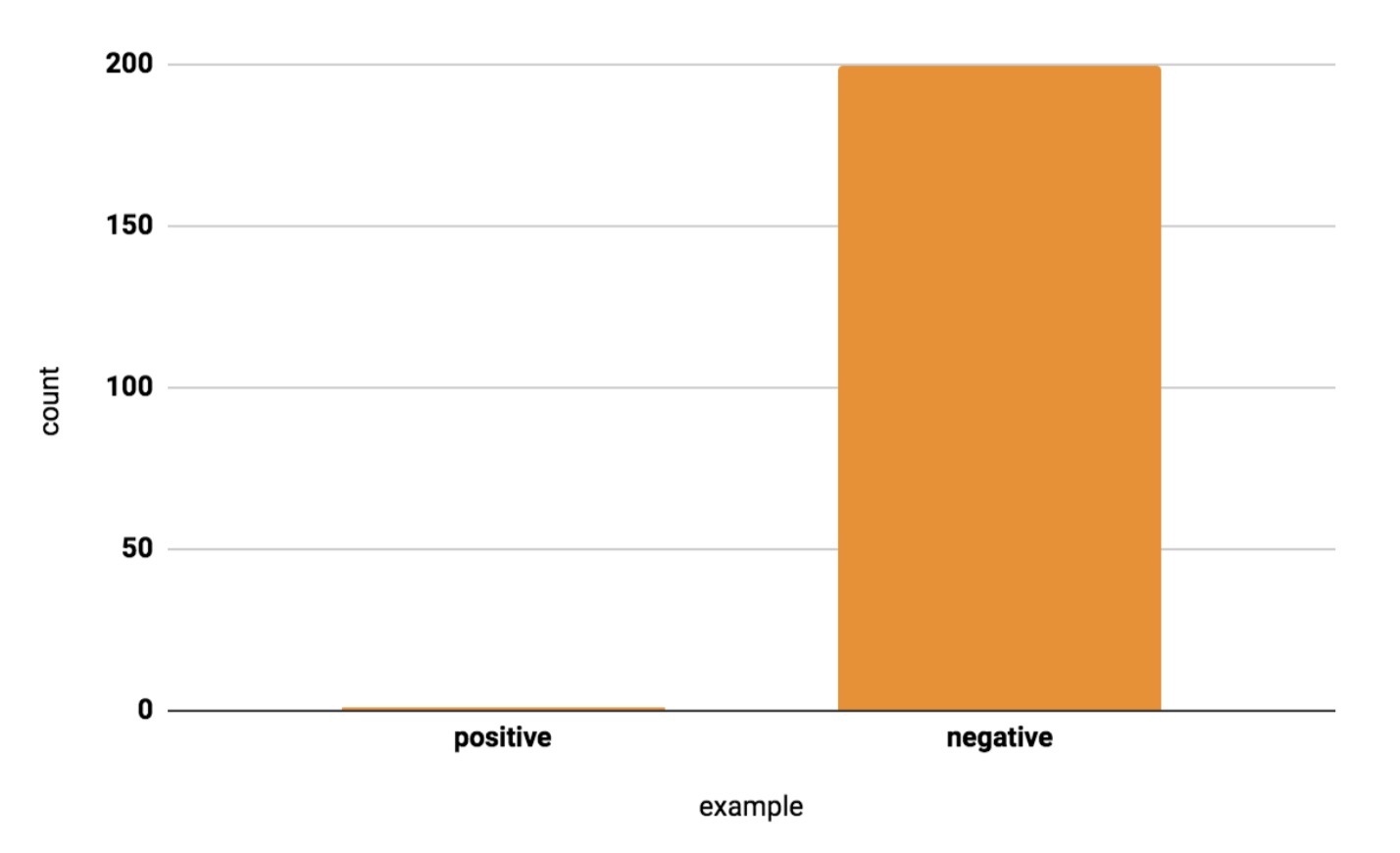
Cara paling simpel untuk mengatasi skewness adalah dengan menyamakan proporsi kelas mayoritas dengan kelas minoritas. Untuk teknik lebih lanjut dalam mengatasi skewness atau imbalance data, Anda bisa membacanya di tautan ini