
Untuk mencoba menggunakan PCA kita bisa memakai library SKLearn. Pada latihan ini kita akan menggunakan dataset Iris seperti yang kita gunakan pada modul sebelumnya.
Pada environment Colab kita impor library yang dibutuhkan.
- from sklearn.decomposition import PCA
- from sklearn.model_selection import train_test_split
- from sklearn import datasets
Kemudian kita masukkan data dan bagi data menjadi train set dan test set.
- iris = datasets.load_iris()
- atribut = iris.data
- label = iris.target
- # bagi dataset menjadi train set dan test set
- X_train, X_test, y_train, y_test = train_test_split(
- atribut, label, test_size=0.2)
Kita akan menggunakan model Decision Tree dan menghitung berapa akurasinya tanpa menggunakan PCA. Akurasi tanpa PCA adalah 0.9666. Akurasi dari model Anda mungkin berbeda dengan keluaran di bawah.
- from sklearn import tree
- decision_tree = tree.DecisionTreeClassifier()
- model_pertama = decision_tree.fit(X_train, y_train)
- model_pertama.score(X_test, y_test)
Tampilan hasil akurasi tanpa PCA dari kode di atas sebagai berikut.

Kemudian kita akan menggunakan PCA dan menghitung variance dari setiap atribut. Hasilnya adalah 1 atribut memiliki variance sebesar 0.919, yang berarti atribut tersebut menyimpan informasi yang tinggi dan jauh lebih signifikan dari atribut lain.
- # membuat objek PCA dengan 4 principal component
- pca = PCA(n_components=4)
- # mengaplikasikan PCA pada dataset
- pca_attributes = pca.fit_transform(X_train)
- # melihat variance dari setiap atribut
- pca.explained_variance_ratio_
Hasil dari setiap atributnya menjadi sebagai berikut.
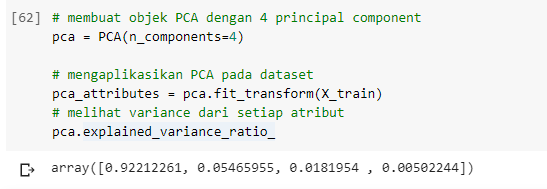
Melihat dari variance sebelumnya kita bisa mengambil 2 principal component terbaik karena total variance nya adalah 0.969 yang sudah cukup tinggi.
- pca = PCA(n_components = 2)
- X_train_pca = pca.fit_transform(X_train)
- X_test_pca = pca.fit_transform(X_test)
Kita akan menguji akurasi dari classifier setelah menggunakan PCA.
- model2 = decision_tree.fit(X_train_pca, y_train)
- model2.score(X_test_pca, y_test)
Hasil pengujian akurasi setelah menggunakan PCA menjadi seperti di bawah ini.
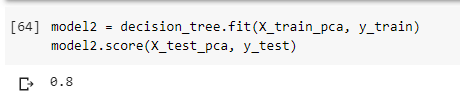
Dari percobaan di atas bisa kita lihat bahwa dengan hanya 2 principal component atau 2 atribut saja model masih memiliki akurasi yang tinggi. Dengan principal component kamu bisa mengurangi atribut yang kurang signifikan dalam prediksi dan mempercepat waktu pelatihan sebuah model machine learning